Calcul des compositions
| Afin d’illustrer les propos ci-après, un outil tableur développé pour les caractérisations d’OMr est mis à disposition par l’ADEME avec ce guide. Cet outil, prêt à l’emploi permet de calculer la composition de chaque échantillon, la composition moyenne du flux d’OMr ainsi que si besoin la composition des déchets par sous-population. |
L’outil est construit pour une campagne de 10 échantillons mais peut-être modifié par les utilisateurs. Il n’est pas proposé dans ce guide d’outil pour les caractérisations de bennes de déchèterie mais les principes de calcul sont identiques à ceux d’une campagne sur les OMr. |
Calcul de la composition des échantillonsPour chaque échantillon, les différents éléments le constituant sont criblés, sous-échantillonnés, et triés selon leur appartenance aux catégories définies par la méthodologie retenue. La masse totale de chaque catégorie est mesurée afin de définir sa part entrant dans la composition de l’échantillon. Le calcul de la composition globale de l’échantillon doit donc respecter la décomposition mise en œuvre lors de sa caractérisation. Il est en particulier important de tenir compte des différentes réductions que l’échantillon a pu subir. Si le tri ne porte que sur une partie du volume initial de l’échantillon (comme c’est le cas dans les méthodes normées de tri), il conviendra d’utiliser le ratio de réduction dans le calcul, pour que les résultats restent représentatifs de l’échantillon dans son intégralité. La composition de l’échantillon est calculée à partir de la part de chaque catégorie dans chaque tranche granulométrique pondérée par le poids de la tranche au sein de l’échantillon. Les règles de calculs sont précisément définies dans chacune des normes de caractérisation indiquées dans les chapitres précédents. |
Calcul de(s) composition(s) moyenne(s)La composition moyenne pourra être déterminée en faisant la moyenne des résultats de composition en pourcentage par échantillon. Des moyennes intermédiaires pourront être calculées en regroupant des échantillons possédant des caractéristiques communes (typologie d’habitat, saisonnalité, etc.). Si un échantillon se distingue fortement des autres et modifie fortement les valeurs moyennes, il est intéressant de noter ses effets et de choisir ou non de l’écarter. Afin d’obtenir des résultats fiables pour toutes les sous-populations, la répartition des échantillons entre ces dernières peut ne pas être au prorata du tonnage. Il conviendra alors, pour pallier ce problème, de pondérer les moyennes des compositions de déchet par sous-populations par les tonnages collectés dans chacune de ces sous-populations.
La moyenne pondérée sera égale à la somme des valeurs de composition de chaque échantillon multipliée par le tonnage collecté associé à l’échantillon, cette somme étant divisée par la somme des tonnages utilisés.
|
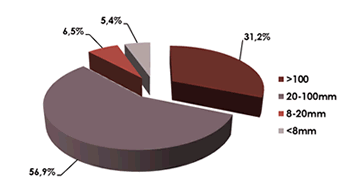
Exemple de présentation des résultatsQuelques exemples de présentation de résultats attendus dans le rapport.
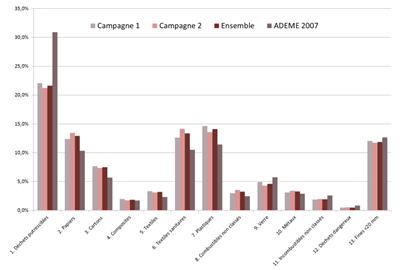
Comparaison des compositions de 2 campagnes |
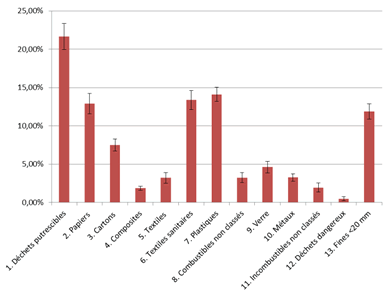
Evaluation de la précision des résultatsLa construction des intervalles de confiance, calculés à partir de la variance et du nombre d’échantillons, permet de compléter les analyses ci-avant. La construction des intervalles de confiance impose de connaitre la loi qui régit la distribution des données, en particulier si celles-ci répondent à une loi normale ou non (données gaussiennes, distribution équilibrée autour de la moyenne). En fonction de cela, l’intervalle est respectivement calculé soit avec le quantile de Student, soit avec l’inégalité de Bienaymé Tchebychev. La normalité des données peut être testée par exemple avec le test de Shapiro Wilk. Cependant, pour un nombre d’échantillons :
Plus ces intervalles seront réduits, plus les résultats seront fiables et robustes. Ces résultats peuvent être présentés sous la forme suivante :
Présentation de composition moyenne avec intervalles de confiance |
Matrice de conversion sec/humidePour le tri des OMr, deux méthodes de tri sont possibles, l’une sur produits humides et la seconde sur produits secs. Il est important de bien indiquer dans le rapport la méthode choisie, et, si possible, la démarche qui a conduit à ce choix. Une composition ne peut être présentée sans que la méthode de tri n’apparaisse car les résultats des deux méthodes ne peuvent être comparés en l’état. S’il est nécessaire de faire des comparaisons avec des données obtenues selon l’une des deux méthodes, il faudra convertir les résultats donnés par le tri sur sec en « résultats sur humide » ou inversement. Cette conversion se fera en utilisant une matrice développée à cet effet (disponible sur demande auprès de l’AFNOR). Si le taux d’humidité d’un échantillon n’est pas connu, la conversion n’est pas possible. De même, la conversion n’est pas possible si la grille de tri ne correspond pas à celle de la matrice de conversion. En outre, à l’usage, il apparaît que les données de référence de cette matrice mériteraient d’être affinées dans la mesure où les retours d’expérience donnent des résultats parfois sujets à interrogation. |